用户交互
Linux(输出)
|
|
print是一个常用函数,其功能就是输出括号中得字符串。(在Python 2.x中,print还可以是一个关键字,可写成print ‘Hello World!’)
写入以下内容,保存并且退出。
|
|
Python提供了一个input(),可以让用户输入字符串,并存放到一个变量里。比如输入用户的名字:
|
|
Python2.7下的raw_input与input
|
|
注意看python2.7在执行input函数式我们第一次输入Adair是有报错的,然后我重新定义一个变量n赋值为Adair然后在执行name1=input(“Please input your name:”)输入n把n的值传入了,没有报错,也可以正常打印,说明一个问题在Python2.7中input里你传入的参数都会被认为是变量,所以重新定义就不会报错
实例:打印用户输入用户名和密码
|
|
注释
单行注释
例子:
|
|
多行注释
例子:
|
|
同样的Python注释语句,可以采用 单引号(‘)、双引号(”)、三单双引号(”””),被注释的语句是不被执行的。
行与缩进
学习Python与其他语言最大的区别就是,Python的代码块不使用大括号({})来控制类,函数以及其他逻辑判断。python最具特色的就是用缩进来写模块。
前面我们在写用户交互程序的时候已经说到了缩进在 python 语言中的重要性,现在我们再来总结一下 Python 缩进的规则:
Python 是强制缩进的语言,它通过缩进来确定一个新的逻辑层次的开始和结束,这也是python 语言的最重要的特色之一
同一逻辑层次级别的代码缩进必须保持一致
顶层逻辑级别的代码必须不能有缩进(新行的开始不能有空格)
整个程序的缩进风格应保持一致,一般为 4 个空格或 2 个空格,官方的推荐是用 4 个空格,当然用 tab 键也可以,但是在 Windows 上的 tab 键和 Linux 上的不一致,会导致你在Windows 上开发的程序 copy 到 Linux 上后运行出错,所以还是建议用 4 个空格。
变量与赋值
变量
整个程序的缩进风格应保持一致,一般为在计算机中,变量就是用来在程序运行期间存储各种需要临时保存可以不断改变的数据的标识符,一个变量应该有一个名字,并且在内存中占据一定的存储单元,在该存储单元中存放变量的值。请注意区分变量名和变量值这两个不同的概念,看下图: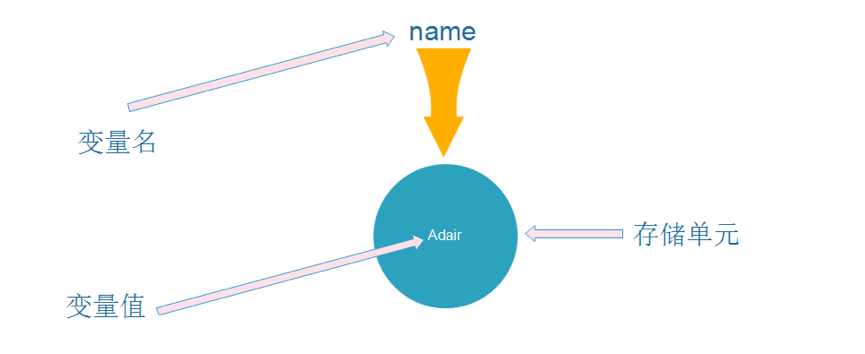
声明变量
声明一个变量为name 值为:adair
查看变量内存地址:
常量
刚才说到了变量,还有一概念就是常量,所谓常量就是不能变的变量,比如常用的数学常数π就是一个常量。在 Python 中,通常用全部大写的变量名表示常量:
PI=3.14159265359
但事实上 PI 仍然是一个变量, 根本没有任何机制保证 不会被改变,所以,用全部大写的变量名表示常量只是一个习惯上的用法,如果你一定要改变变量PI的值,也没人能拦住你。
变量的命名规则
- 变量名只能是字母,数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
不可定义的变量
以下关键字不能声明为变量名(keyword模块,可以输出当前版本的所有关键字)
数据类型
数字
int (整数型)
在32位机器上,整数的位数为32位,取值范围为-231~231-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-263~263-1,即-9223372036854775808~9223372036854775807
float (浮点型)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下 的一位表示符号。
long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
布尔值
布尔值和布尔代数的表示完全一致,一个布尔值只有True、False两种值,要么是True,要么是False,在Python中,可以直接用True、False表示布尔值(请注意大小写),也可以通过布尔运算计算出来:
字符串
字符串类型是python的序列类型,他的本质就是字符序列,而且python的字符串类型是不可以改变的,你无法将原字符串进行修改,但是可以将字符串的一部分复制到新的字符串中,来达到相同的修改效果。
使用引号创建字符串
创建字符串类型可以使用单引号或者双引号又或者三引号来创建,实例如下:
单引号
1234>>> name = 'adair'>>> type(name)<class 'str'>>>>双引号
1234>>> name = "adair">>> type(name)<class 'str'>>>>三引号
123name = """adair"""type(name)<class 'str'>
字符串所具备的方法
capitalize(self):
把值得首字母变大写123name = 'adair'name.capitalize()'Adair'center(self, width, fillchar=None):
内容居中,width:字符串的总宽度;fillchar:填充字符,默认填充字符为空格。1234567891011121314# 定义一个字符串变量,名为"name",内容为"hello word"name = "hello word"# 输出这个字符串的长度,用len(value_name)len(name)10# 字符串的总宽度为10,填充的字符为"*"name.center(10,"*")'hello word'# 如果设置字符串的总长度为11,那么减去字符串长度10还剩下一个位置,这个位置就会被*所占用name.center(11,"*")'*hello word'# 是从左到右开始填充name.center(12,"*")'*hello word*'count(self, sub, start=None, end=None):
sub –> 搜索的子字符串
start –> 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。
end –> 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。
用于统计字符串里某个字符出现的次数,可选参数为在字符串搜索的开始与结束位置。123456name="hello word"name.count("l") # 默认搜索出来的"l"是出现过两次的2# 如果指定从第三个位置开始搜索,搜索到第六个位置,"l"则出现过一次name.count("l",3,6)1encode(self, encoding=None, errors=None):
编码,针对unicode1234# 定义一个变量内容为中文temp = "中文"# 把变量的字符集转化为UTF-8temp_unicode = temp.decode("utf-8")endswith(self, suffix, start=None, end=None):
suffix –> 后缀,可能是一个字符串,或者也可能是寻找后缀的tuple。
start –> 开始,切片从这里开始。
end –> 结束,片到此为止。
于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回True,否则返回False。12345678910string="hello word"# 判断字符串中是否已"d"结尾,如果是则返回"True"string.endswith("d")True# 判断字符串中是否已"t"结尾,不是则返回"False"string.endswith("t")False# 制定搜索的位置,实则就是从字符串位置1到7来进行判断,如果第七个位置是"d",则返回True,否则返回Falsestring.endswith("d",1,7)Falsefind(self, sub, start=None, end=None):
str –> 指定检索的字符串
beg –> 开始索引,默认为0。
end –> 结束索引,默认为字符串的长度。
检测字符串中是否包含子字符串str,如果指定beg(开始)和end(结束)范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。1234567string="hello word"# 返回`o`在当前字符串中的位置,如果找到第一个`o`之后就不会再继续往下面寻找了string.find("o")4# 从第五个位置开始搜索,返回`o`所在的位置string.find("o",5)7index(self, sub, start=None, end=None):
str –> 指定检索的字符串
beg –> 开始索引,默认为0。
end –> 结束索引,默认为字符串的长度。
检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果str不在 string中会报一个异常。123456789string="hello word"# 返回字符串所在的位置string.index("o")4# 如果查找一个不存在的字符串那么就会报错string.index("a")Traceback (most recent call last):File "<stdin>", line 1, in <module>ValueError: substring not foundisalnum(self):
法检测字符串是否由字母和数字组成,如果string至少有一个字符并且所有字符都是字母或数字则返回True,否则返回False12345678string="hes2323"# 如果存在数字或字母就返回`True`,否则返回`False`string.isalnum()True# 中间有空格返回的就是False了string="hello word"string.isalnum()Falseisalpha(self):
检测字符串是否只由字母组成。12345678# 如果全部都是字母就返回`True`string="helloword"string.isalpha()True# 否则就返回Falsestring="hes2323"string.isalpha()Falseisdigit(self):
检测字符串是否只由数字组成1234567# 如果变量里面都是数字就返回`True`,否则就返回`False`string="hes2323"string.isdigit()Falsestring="2323"string.isdigit()Trueislower(self):
检测字符串是否由小写字母组成1234567# 如果变量内容全部都是小写字母就返回`True`,否则就返回`False`string="hesasdasd"string.islower()Truestring="HelloWord"string.islower()Falseisspace(self):
检测字符串是否只由空格组成1234567# 如果变量内容由空格来组成,那么就返回`True`否则就返回`False`string=" "string.isspace()Truestring="a"string.isspace()Falseistitle(self):
检测字符串中所有的单词拼写首字母是否为大写,且其他字母为小写。1234567# 如果变量的内容首字母是大写并且其他字母为小写,那么就返回`True`,否则会返回`False`string="Hello Word"string.istitle()Truestring="Hello word"string.istitle()Falseisupper(self):
检测字符串中所有的字母是否都为大写。1234567# 如果变量值中所有的字母都是大写就返回`True`,否则就返回`False`string="hello word"string.isupper()Falsestring="HELLO WORD"string.isupper()Truejoin(self, iterable):
将序列中的元素以指定的字符连接生成一个新的字符串。123string=("a","b","c")'-'.join(string)'a-b-c'ljust(self, width, fillchar=None):
width –> 指定字符串长度
fillchar –> 填充字符,默认为空格
返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串。123456string="helo word"len(string)9# 定义的长度减去字符串的长度,剩下的就开始填充string.ljust(15,'*')'helo word******'lower(self):
转换字符串中所有大写字符为小写。1234# 把变量里的大写全部转换成小写string="Hello WORD"string.lower()'hello word'lstrip(self, chars=None):
chars –> 指定截取的字符
用于截掉字符串左边的空格或指定字符1234# 从左侧开始删除匹配的字符串string="hello word"string.lstrip("hello ")'word'partition(self, sep):
str –> 指定的分隔符
用来根据指定的分隔符将字符串进行分割,如果字符串包含指定的分隔符,则返回一个3元的tuple,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串。1234# 返回的是一个元组类型string="www.ansheng.me"string.partition("ansheng")('www.', 'ansheng', '.me')replace(self, old, new, count=None):
old –> 将被替换的子字符串
new –> 新字符串,用于替换old子字符串
count –> 可选字符串, 替换不超过count次12345678910111213141516171819202122把字符串中的 old(旧字符串)替换成new(新字符串),如果指定第三个参数max,则替换不超过max次string="www.ansheng.me"# 把就字符串`www.`换成新字符串`https://`string.replace("www.","https://")'https://ansheng.me'# 就字符串`w`换成新字符串`a`只替换`2`次string.replace("w","a",2)'aaw.ansheng.me'```python* rfind(self, sub, start=None, end=None):str –> 查找的字符串beg –> 开始查找的位置,默认为0end –> 结束查找位置,默认为字符串的长度返回字符串最后一次出现的位置,如果没有匹配项则返回-1。```pythonstring="hello word"# rfind其实就是反向查找string.rfind("o")7# 指定查找的范围string.rfind("o",0,6)4rindex(self, sub, start=None, end=None):
str –> 查找的字符串
beg –> 开始查找的位置,默认为0
end –> 结束查找位置,默认为字符串的长度12345678910返回子字符串str在字符串中最后出现的位置,如果没有匹配的字符串会报异常,你可以指定可选参数[beg:end]设置查找的区间。string="hello word"# 反向查找索引string.rindex("o")7# 如果没有查找到就报错string.rindex("a")Traceback (most recent call last):File "<stdin>", line 1, in <module>ValueError: substring not foundrjust(self, width, fillchar=None):
width –> 指定填充指定字符后中字符串的总长度
fillchar –> 填充的字符,默认为空格12345678返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串。如果指定的长度小于字符串的长度则返回原字符串。string="hello word"len(string)10string.rjust(10,"*")'hello word'string.rjust(12,"*")'**hello word'rsplit(self, sep=None, maxsplit=None):
str--> 分隔符,默认为空格 *num*–> 分割次数
从右到左通过指定分隔符对字符串进行切片,如果参数num有指定值,则仅分隔num个子字符串12345string="www.ansheng.me"string.rsplit(".",1)['www.ansheng', 'me']string.rsplit(".",2)['www', 'ansheng', 'me']rstrip(self, chars=None):
chars –> 指定删除的字符
删除string字符串末尾的指定字符(默认为空格).1234# 从尾部开始匹配删除string="hello word"string.rstrip("d")'hello wor'split(self, sep=None, maxsplit=None):
str--> 分隔符,默认为空格 *num*–> 分割次数
从左到右通过指定分隔符对字符串进行切片,如果参数num有指定值,则仅分隔num个子字符串1234567string="www.ansheng.me"# 指定切一次,以`.`来分割string.split(".",1)['www', 'ansheng.me']# 指定切二次,以`.`来分割string.split(".",2)['www', 'ansheng', 'me']splitlines(self, keepends=False):
num –> 分割行的次数
按照行分隔,返回一个包含各行作为元素的列表,如果num指定则仅切片num个行.12345678910# 定义一个有换行的变量,`\n`可以划行string="www\nansheng\nme"# 输出内容print(string)wwwanshengme# 把有行的转换成一个列表string.splitlines(1)['www\n', 'ansheng\n', 'me']startswith(self, prefix, start=None, end=None):
str –> 检测的字符串
strbeg –> 可选参数用于设置字符串检测的起始位置
strend –> 可选参数用于设置字符串检测的结束位置
检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。如果参数 beg 和 end 指定值,则在指定范围内检查。12345string="www.ansheng.me"string.startswith("www")Truestring.startswith("www",3)Falsestrip(self, chars=None):
chars –> 移除字符串头尾指定的字符
移除字符串头尾指定的字符(默认为空格)12345678910string=" www.ansheng.me "string' www.ansheng.me '# 删除空格string.strip()'www.ansheng.me'string="_www.ansheng.me_"# 指定要把左右两边的"_"删除掉string.strip("_")'www.ansheng.me'swapcase(self):
用于对字符串的大小写字母进行转换,大写变小写,小写变大写123string="hello WORD"string.swapcase()'HELLO word'title(self):
返回”标题化”的字符串,就是说所有单词都是以大写开始,其余字母均为小写。123string="hello word"string.title()'Hello Word'translate(self, table, deletechars=None):
table –> 翻译表,翻译表是通过maketrans方法转换而来
deletechars –> 字符串中要过滤的字符列表
根据参数table给出的表(包含 256 个字符)转换字符串的字符, 要过滤掉的字符放到 del 参数中。upper(self):
将字符串中的小写字母转为大写字母123string="hello word"string.upper()'HELLO WORD'zfill(self, width):
width –> 指定字符串的长度。原字符串右对齐,前面填充0
返回指定长度的字符串,原字符串右对齐,前面填充0
格式化字符串例子:
|
|
输出结果:
第二种方式
输出结果:
Ps:字符串是%s;整数%d;浮点数%f
列表
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
创建列表
比如列出各类编程语言:
支持的方法
用dir()函数可以查看此列表能使用的方法
索引
.index用索引来访问list中每一个位置的元素,索引是从0开始的
切片
|
|
追加
.append(self, p_object)用于在列表末尾添加新的对象,obj – 添加到列表末尾的对象,该方法无返回值,但是会修改原来的列表。
|
|
删除最后一个元素
.pop(self, index=None)用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值,index– 可选参数,要移除列表元素的对象,该方法返回从列表中移除的元素对象,可以通过pop(index)指定删除类似remove
指定删除
.remove(self, value)用于移除列表中某个值的第一个匹配项,value – 列表中要移除的对象,该方法没有返回值但是会移除两种中的某个值的第一个匹配项。
|
|
指定插入
.insert(self, index, p_object)用于将指定对象插入列表,index – 对象obj需要插入的索引位置,obj – 要插入列表中的对象,该方法没有返回值,但会在列表指定位置插
次数统计
.count用于统计某个元素在列表中出现的次数,value – 列表中统计的对象,返回元素在列表中出现的次数。
反向存放
.reverse(self)用于反向列表中元素,该方法没有返回值,但是会对列表的元素进行反向排序。
合并
.extend(self, iterable)用于在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表),seq – 元素列表,该方法没有返回值,但会在已存在的列表中添加新的列表内容
排序
.sort(self, cmp=None, key=None, reverse=False)用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数,该方法没有返回值,但是会对列表的对象进行排序。
元组
Python的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
创建元组
|
|
支持的方法
|
|
索引
|
|
切片
|
|
list和tuple互转
|
|
字典
创建字典
每个键与值用冒号隔开(:),每对用逗号分割,整体放在花括号中({})。
键必须独一无二,但值则不必。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
注:type()可以查看变量类型
支持的方法
|
|
清除内容
clear(self),删除字典中的所有元素
浅复制
copy(self),返回一个字典的浅复制
fromkeys(S, v=None):
S –> 字典键值列表
v –> 可选参数, 设置键序列(seq)的值
创建一个新字典,以序列seq中元素做字典的键,value为字典所有键对应的初始值
get(self, k, d=None):
key –> 字典中要查找的键
default –> 如果指定键的值不存在时,返回该默认值值
返回指定键的值,如果值不在字典中返回默认值
has_key(self, k)
(注:3.x已经不存在这个函数)
用于判断键是否存在于字典中,如果键在字典dict里返回true,否则返回false
|
|
items(self)
以列表返回可遍历的(键, 值)元组数组
keys(self)
以列表返回一个字典所有的键。
pop(self, k, d=None)
获取并在字典中移除,k – 要在字典中查找的键。
popitem(self)
获取并在字典中移除
setdefault
setdefault(self, k, d=None)如果key不存在,则创建,如果存在,则返回已存在的值且不修改
update(self, E=None, **F)
更新一个字典到另外一个字典
values(self)
以列表返回字典中的所有值。
删除指定索引的键值对
|
|
获取全部的键值对
|
|
集合
集合(set)
把不同的元素组成一起形成集合,是python基本的数据类型。
集合元素(set elements):组成集合的成员
python的set和其他语言类似, 是一个无序不重复元素集, 基本功能包括关系测试和消除重复元素. 集合对象还支持union(联合), intersection(交), difference(差)和sysmmetric difference(对称差集)等数学运算.
sets 支持 x in set, len(set),和 for x in set。
作为一个无序的集合,set不记录元素位置或者插入点。因此,sets不支持 indexing, slicing, 或其它类序列(sequence-like)的操作。
集合的创建
|
|
集合的具体用法
add(添加元素)
clear(清空集合)
copy(浅拷贝)
difference差异比较
differemce_update差异更新
discard移除指定元素
intersection取交集并且建立新的集合
intersection_update取交集并且更新原来的集合
isdisjoint判断没有交集,没有返回true,有返回false
issubset判断是否为子集
issuperset判断是否为父集
pop移除集合元素
remove删除指定元素集合
symmetric_difference取两个集合的差集,并建立新的元素
symmetric_difference_update取两个集合的差集,更新原来的集合对象
union并集
update更新集合
案例差异对比
|
|
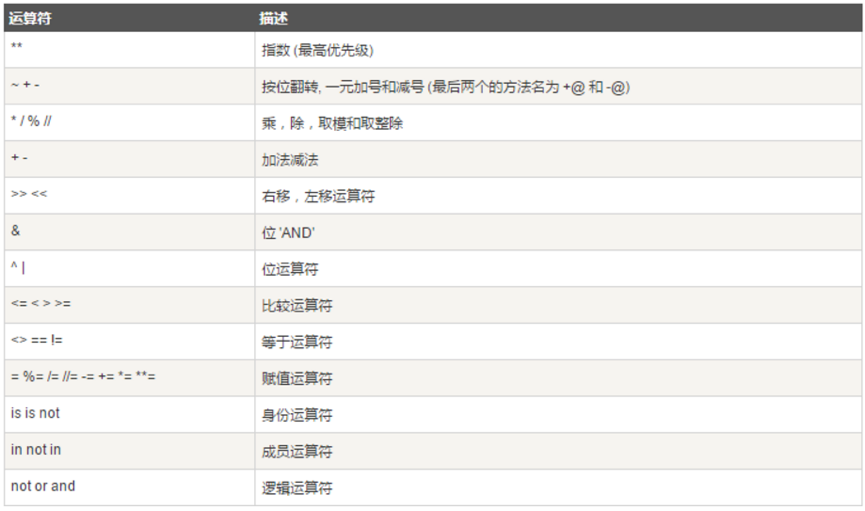
运算符
算术运算
以下假设a为10,b为20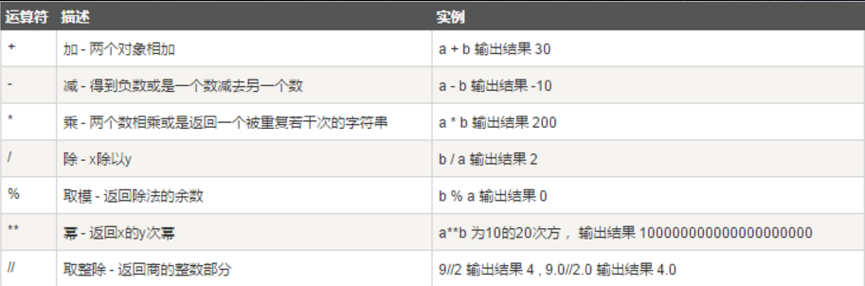
比较运算
以下假设a为10,b为20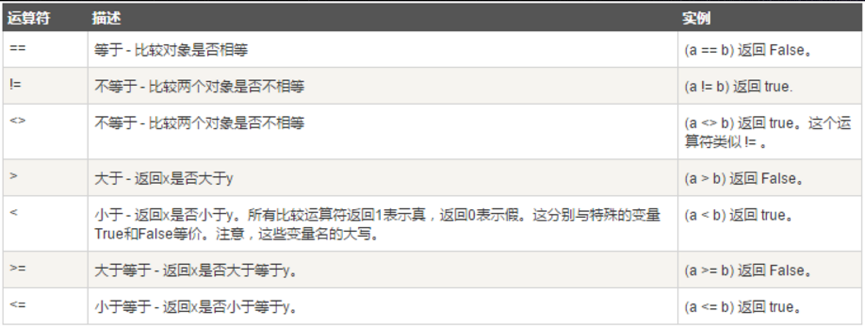
赋值运算符
以下假设a为10,b为20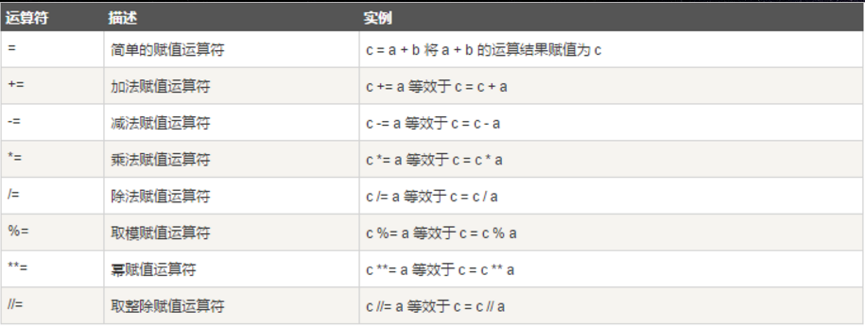
位运算
按位运算符是把数字看作二进制来进行计算的。Python中的按位运算法则如下: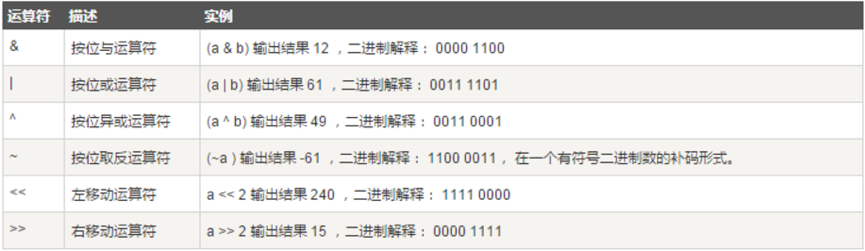
逻辑运算符
Python语言支持逻辑运算符,以下假设变量a为10,变量b为20:
成员运算符

身份运算符
身份运算符用于比较两个对象的存储单元
运算符优先级